NVDA HARUKA用 追加辞書 (2014/03/08版)
投稿者:マーチン 2014年3月9日
カテゴリ:視覚障碍者向け::スクリーンリーダー「NVDA」
カテゴリ:視覚障碍者向け::スクリーンリーダー「NVDA」
※最新記事はこちら 【まほろば】NVDA HARUKA用 追加辞書 (2015/09/21版)
Windows XP / Vista / 7 には、OSに日本語の音声合成エンジンがついてきませんが、Microsoftから無料で提供されている音声エンジン「Microsoft Speech Platform HARUKA」を使うことができます。しかし、「HARUKA」の辞書に登録されている単語が少ないのか、NVDAでよく使われる単語さえも読み間違えてしまいます。
Windows 8 には、最初からSAPI5対応の音声エンジン「HARUKA Desktop」 が付属していて、SAPI5音声として使用でき、「Microsoft Speech Platform HARUKA」の辞書をベースに、改善されているようです。特に英単語の多くは読めるようになりました。しかし、まだ読めない単語があり、スクリーンリーダーとして使うには不十分と感じます。
それらをちょっとでも改善するために、追加辞書を作成しました。この辞書は[読み上げ辞書] [音声]で登録したものと同じですので、[読み上げ辞書] [デフォルト] で登録したものとは共存できます。
●2つの Microsoft Speech Platform
NVDA日本語版には、
- Microsoft Speech Platform
- Haruka (nvdajp)
●Microsoft Speech Platform のインストール
Windows 8 にはインストールする必要はありません。Windows XP / Vista / 7 に Microsoft Speech Platform をインストールには、以下のツールをお勧めします。
●追加辞書のダウンロード
HARUKAで読めない単語を辞書にしました。この辞書は、Windows XP/Vista/7 での音声エンジンで「Microsoft Speech Platform」 か 「Haruka (nvdajp)」を選択したとき、あるいは、Windows8での音声エンジンで「Microsoft Speech API version 5」を、 音声設定で、「Haruka Deaktop」 を選択した時に適用されます。
(1)「NVDA HARUKA用 追加辞書 (2014/3/8版)」をダウンロードして、解凍する。
(2)以下の方法で、ユーザ設定ディレクトリを開く。
(1)「NVDA HARUKA用 追加辞書 (2014/3/8版)」をダウンロードして、解凍する。
- Microsoft Speech Platform用:
mssp-Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka).dic - Haruka (nvdajp)用:
msspeech_tts-Microsoft Server Speech Text to Speech Voice (ja-JP, Haruka).dic
- Haruka Desktop用:
sapi5-Microsoft Haruka Desktop - Japanese.dic
(2)以下の方法で、ユーザ設定ディレクトリを開く。
- インストール版で、Windows7以前の場合は、[Start] [すべてのプログラム] [NVDA] [ユーザ設定ディレクトリを開く] を選択する。
- インストール版で、Windows8以降の場合は、Windowsキーを押して"nvda"と入力して、チャームのメニューから、[NVDAユーザ設定ディレクトリを開く] を選択する。
- ポータブル版の場合は、NVDAフォルダの下の ¥userConfig を開く。
●NVDAの設定 (Microsoft Speech Platform HARUKA の場合)
(1)NVDAを起動する。
(2)NVDA+N [設定] [音声エンジン] を選択して、出力先で ”Haruka (nvdajp)” を指定して、[OK]ボタンを押す。
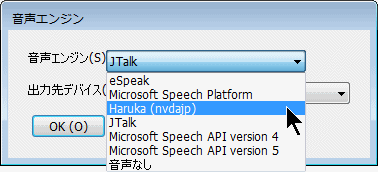
(3)NVDA+N [設定] [音声設定] を選択して、音声で ”Microsoft Server Speech Text to Speech Voice(ja-JP,Haruka)” を指定して、[OK]ボタンを押す。
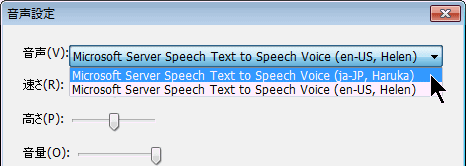
(4)NVDA+N [設定] [読み上げ辞書] [音声辞書] を選択して、単語が登録されていれば、HARUKA用辞書 が読込まれている。
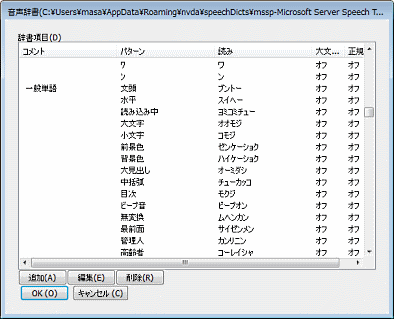
※既にHaruka をNVDAの音声として使用している状態で、ユーザ設定ディレクトリにファイルを追加した場合には、NVDAを起動し直すか、音声を選択し直す必要があります。
(2)NVDA+N [設定] [音声エンジン] を選択して、出力先で ”Haruka (nvdajp)” を指定して、[OK]ボタンを押す。
(3)NVDA+N [設定] [音声設定] を選択して、音声で ”Microsoft Server Speech Text to Speech Voice(ja-JP,Haruka)” を指定して、[OK]ボタンを押す。
(4)NVDA+N [設定] [読み上げ辞書] [音声辞書] を選択して、単語が登録されていれば、HARUKA用辞書 が読込まれている。
※既にHaruka をNVDAの音声として使用している状態で、ユーザ設定ディレクトリにファイルを追加した場合には、NVDAを起動し直すか、音声を選択し直す必要があります。
●NVDAの設定 (HARUKA Desktop の場合)
(1)NVDAを起動する。
(2)NVDA+N [設定] [音声エンジン] を選択して、出力先で ”Microsoft Speech API Version 5” を指定して、[OK]ボタンを押す。
(3)NVDA+N [設定] [音声設定] を選択して、音声で ”Microsoft Server Speech Text to Speech Voice(ja-JP,Haruka)” を指定して、[OK]ボタンを押す。
(4)NVDA+N [設定] [読み上げ辞書] [音声辞書] を選択して、単語が登録されていれば、HARUKA用辞書 が読込まれている。
※既にHaruka をNVDAの音声として使用している状態で、ユーザ設定ディレクトリにファイルを追加した場合には、NVDAを起動し直すか、音声を選択し直す必要があります。
(2)NVDA+N [設定] [音声エンジン] を選択して、出力先で ”Microsoft Speech API Version 5” を指定して、[OK]ボタンを押す。
(3)NVDA+N [設定] [音声設定] を選択して、音声で ”Microsoft Server Speech Text to Speech Voice(ja-JP,Haruka)” を指定して、[OK]ボタンを押す。
(4)NVDA+N [設定] [読み上げ辞書] [音声辞書] を選択して、単語が登録されていれば、HARUKA用辞書 が読込まれている。
※既にHaruka をNVDAの音声として使用している状態で、ユーザ設定ディレクトリにファイルを追加した場合には、NVDAを起動し直すか、音声を選択し直す必要があります。
●ご協力のお願い
この追加辞書は、個人的な使用で見つけた読み間違いを、改善しようとしたものです。もし、「私はこんな単語を登録しています」という情報があれば、連絡をいただけると助かります。次バージョン以降の追加辞書に入れさせてもらうことも検討します。よろしくお願いします。
●辞書登録の仕方
(1)NVDAメニューから、[設定] [読み上げ辞書] を選択し、[デフォルト] を選択する。
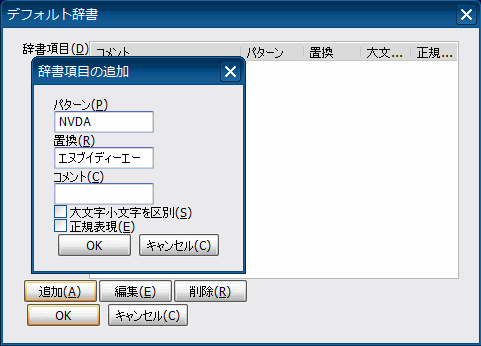
(2)[追加]ボタンをクリックし、パターン、置換、コメントに入力し、
□大文字小文字の区別
□正規表現
にチェックを入れるか入れないかを選択して、[OK]ボタンをクリックする。
- デフォルト: NVDAのすべての読み上げに適用
- 音声: 現在使用中の音声エンジンに適用
- 一時辞書: 一時的なもので、NVDAを再起動すると失われる
(2)[追加]ボタンをクリックし、パターン、置換、コメントに入力し、
□大文字小文字の区別
□正規表現
にチェックを入れるか入れないかを選択して、[OK]ボタンをクリックする。
●辞書の評価順
辞書内、辞書間の評価順は以下の通りです。
・同じ辞書の中では、上から順に評価されます。
・辞書の間では、一時辞書 → 音声 → デフォルト の順に評価されます。
短い単語を前のほうに登録したり、正規表現を使ったルールの登録順を間違えると、期待通りの読み上げをしてくれません。辞書が大きくなってくると、管理が難しくなってきます。・辞書の間では、一時辞書 → 音声 → デフォルト の順に評価されます。
●辞書登録例
◆正規表現を使わない
もっとも簡単なのは、正しく読んでくれない単語をそのまま登録することです。
パターン: 小文字
置換: コモジ
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
置換: コモジ
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
◆正規表現を使う-1
MSSpeech HARUKA では、「表」は「オモテ」と読み上げますが、特定の熟語の後の「表」は、「ヒョウ」と読んでほしい場合があります。このような例はたくさんあるので、正規表現を使えば、それらをまとめて表現できます。
パターン: (早見|番組|時刻|一覧|関連|料金|座席|成績|順位|対応)表
置換: ¥1ヒョー
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
置換: ¥1ヒョー
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
◆正規表現を使う-2
パターン: 全て
置換: すべて
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
とすると、「全」の前に他の漢字があり熟語を作っている場合にも置換してします。直前には漢字がない、あるいは行頭である場合のみ置換することでこの誤りは避けられます。置換: すべて
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
パターン: (^|[^一-龠])全て
置換: ¥1すべて
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
置換: ¥1すべて
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
●サンプル辞書の説明
◆HARUKA辞書の不具合を修正
・半角カタカナ
半角カタカナを読み上げてくれないので、全角カタカナに置換します。
・省略語 HARUKAに登録されている単語の中に、短いアルファベットを省略語とみなしているものがあり、変な読み方になる場合がありますので、それらをアルファベット読みに訂正しています。
| 単語 | 読み | 訂正後 |
|---|---|---|
| PS | プレイステーション | ピーエス |
| MP | マルチプロセッサ | エムピー |
| DB | デシベル | デービー |
| T | トン | ティー |
◆少し高度な置き換え
・パソコン用語
・日付の読み上げ
・位取り
アルファベットの短い単語を登録する際には、予期しない置き換えで副作用を起こさないかを十分考える必要があります。
例えば、キーボードの DEL を『デリート』と読んでほしい場合、単純に、
例えば、キーボードの DEL を『デリート』と読んでほしい場合、単純に、
パターン: DEL
置換: デリート
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
で登録すると、delta (デルタ) を、『デリートティーエー』と読んでしまいます。DEL の前が、行頭かアルファベット以外で、DEL の後が行末かアルファベット以外であることを判断すれば、このような置換は発生しなくなります。そのためには、置換: デリート
□大文字小文字の区別 (チェックなし)
□正規表現 (チェックなし)
パターン: (^|[^A-Z])DEL(?=$|[^A-Z])
置換: ¥1デリート
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
のように登録します。また、以下のようにすれば、全角文字でも読み上げます。置換: ¥1デリート
□大文字小文字の区別 (チェックなし)
■正規表現 (チェックあり)
パターン: (^|[^A-ZA-Z])(DEL|DEL)(?=$|[^A-ZA-Z])
置換: ¥1デリート
置換: ¥1デリート
・日付の読み上げ
『05月05日(木)』と書かれていると、MSSpeech HARUKA は、『レイゴツキ レイゴニチ キ』と読み上げます。そこで、以下の3個のルールを登録します。
『5月5日モクヨー』と置換され、『ゴガツ イツカ モクヨー』と読むようになります。
| パターン | 置換 | 大小文字の区別 | 正規表現 |
|---|---|---|---|
| [(¥[]木[)¥]] | モクヨー | オフ | オン |
| [00](¥d月¥d{1,2}日) | ¥1 | オフ | オン |
| (¥d{1,2}月)[00](¥d日) | ¥1¥2 | オフ | オン |
・位取り
MSSpeech HARUKA では、5桁以上の連続した数字を4桁ごとに読み上げてしまいます。3桁ごとにカンマを入れることで正しく読むことができます。但し、4桁の連続数字にもカンマを入れると、西暦の年号を正しく読まなくなってしまうので、変換しないようにします。
・7桁以上
・7桁以上
パターン: (¥d)(?=(¥d{3}){2,}(?!¥d))
置換: ¥1,
・5~6桁置換: ¥1,
パターン: (¥d{2,})(?=(¥d{3})(?!¥d))
置換: ¥1,
置換: ¥1,
●サンプル辞書の内容
※一部割愛しています

